| Description | | | Download |
As of version 1.0.5 (February, 2003), gretl offers support for the data sets associated with Damodar Gujarati's Basic Econometrics (4th edition, McGraw-Hill, 2003). This page explains what gretl's support for the Gujarati data sets amounts to.
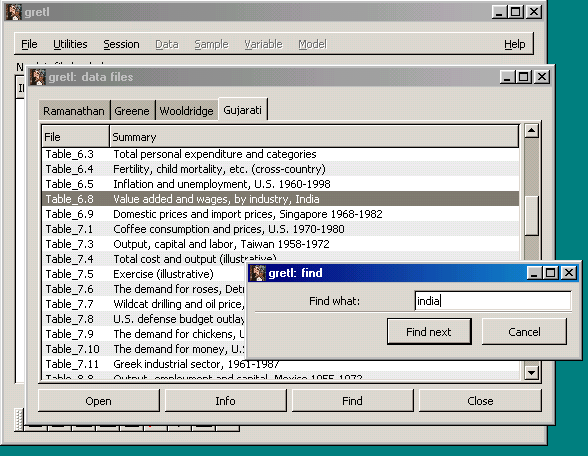
First (as with the data sets from the introductory econometrics texts by Ramu Ramanathan and Jeffrey Wooldridge), gretl offers a searchable index of the files, where each one is identified by a short description.
Having found a data set of interest, one can click on "Info" to get more information about the data.
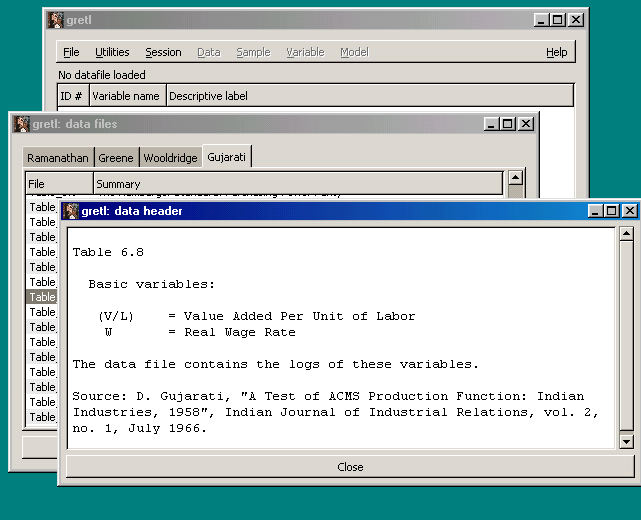
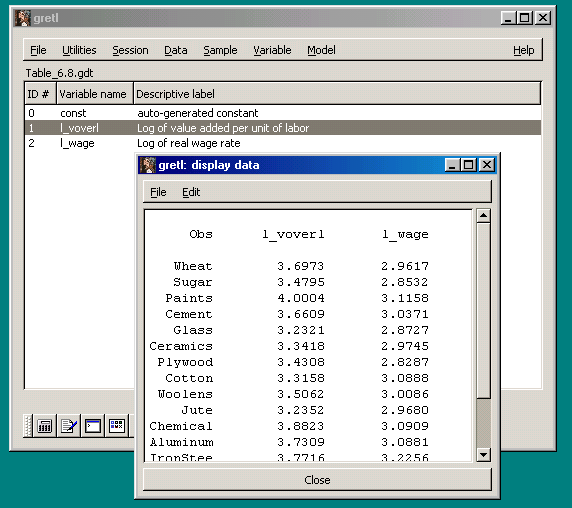
Clicking "Open" opens the data set in gretl's workspace. In this view, each variable has a short description. Where the observations are explicitly identified in the data file (as in this cross-section of Indian industries), the observation labels are shown when the data are listed.
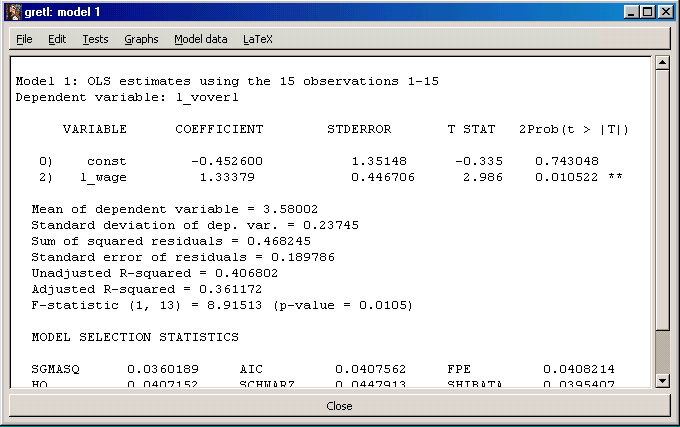
Finally we show the regression that is called for in Problem 6.14 in the Gujarati text.
Here are the Gujarati data sets for gretl:
Self-installer for the MS Windows version of gretl: gujarati_data.exe. To install: simply run the executable file (you should install gretl first).
Gzipped tar archive for gretl on Linux/unix: gujarati_data.tar.gz. To install: unpack the archive in either the "system" gretl data directory or in your gretl user directory. For example:
cd /usr/share/gretl/data && tar xvfz gujarati_data.tar.gz
Allin Cottrell <cottrell@wfu.edu>, February 24, 2003.